![[Tensorflow] 텐서플로우 데이터셋 불러오기 (데이터 변형 x, 전이학습)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FoJ01K%2FbtrVLvYirwl%2FkIvbZsIlfGqIIkTefHJIfK%2Fimg.png)
https://www.tensorflow.org/datasets/catalog/overview
데이터세트 | TensorFlow Datasets
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trade
www.tensorflow.org
텐서플로우 홈페이지의 있는 데이터셋을 정석적인 방법대로 코랩으로 불러와보자.
텐서플로우 홈페이지에 소개되어 있는 메뉴얼과 구글링 결과들을 종합해보았다.
지난 포스팅에서는 텐서플로우 데이터셋을 활용하는 방법을 몰라서 나에게 친숙한 numpy로 모두 바꾸어서 분석하는 방법을 포스팅하였다.
2022.11.29 - [대학원 공부/텐서플로] - [Tensorflow] 텐서플로 데이터셋 불러오기
[Tensorflow] 텐서플로 데이터셋 불러오기
텐서플로우 공식 홈페이지에 소개되어 있는 데이터셋을 가져오는 포스팅이 많이 없기도 했고, 일반 데이터셋이랑은 다루는 방법이 많이 달라서 끄적여본다. 처음에 이런 형식의 데이터셋과 친
ozzzih.tistory.com

사실 위 방법은 정말 효율적이지 못한 방법이다. 용량이 작은 데이터셋은 감당할 수 있지만 조금이라도 용량이 커지면 코랩이 터져버리는 현상이 발생한다ㅎㅎ
이제부터는 용량 상관없이 텐서플로 데이터셋을 정말 편하고 간단하게 분석하는 방법에 대해 소개하겠다.
먼저 분석에 필요한 라이브러리를 호출한다.
# 필요한 라이브러리
import tensorflow as tf
import tensorflow_datasets as tfds
import os
import numpy as np
import matplotlib.pyplot as plt저번 포스팅에서와 같이 'deep_weeds' 데이터셋을 불러와준다.
데이터셋 설명은 아래를 참조한다.
https://www.tensorflow.org/datasets/catalog/deep_weeds
깊은 잡초 | TensorFlow Datasets
DeepWeeds 데이터 세트는 인접한 식물군과 함께 호주 고유의 8가지 잡초 종을 캡처하는 17,509개의 이미지로 구성됩니다. 선택한 잡초 종은 퀸즐랜드 주 전역의 목가적인 초원에 서식합니다. 이미지
www.tensorflow.org
#데이터 불러오기, 교재 379~382페이지 참조
tfds.disable_progress_bar()
(raw_train, raw_test), metadata = tfds.load('deep_weeds',
split = ['train[:70%]', 'train[70%:'], with_info=True, as_supervised=False)
print(raw_train)
print(raw_test)
print(metadata)train의 70%는 raw_train으로 배정하였고, train의 30%는 raw_test로 배정하였다.

데이터셋 소개글로 가보면 위와 같이 train데이터로만 구성되어 있기 때문에 이 train을 임의로 train과 test데이터로 분리하였다.
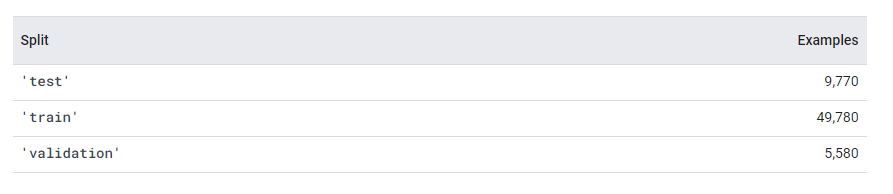
위 사진과 같이 test, train, validation이 나누어져있다면 그대로 사용해도 되고, train을 train과 test로 분류하여 사용해도 된다. 즉, 사용자가 뜻하는 대로 데이터를 분류할 수 있음!
이 raw_train과 raw_test의 형식을 보면 다음과 같다.

이전 포스팅에서 겁먹었었던 PrefetchDataset형태이다.
shape는 (256, 256, 3)이다. 즉 크기가 256x256으로 일정하고 컬러가 있는 그림임을 의미한다.
이제 이 데이터를 분석에 사용할 수 있는 형태로 변형하는 작업을 하겠다.
normalize라는 함수를 만드는 작업이다.
데이터셋을 image와 label로 분리하고, image의 크기를 변경 후 정규화하는 함수이다.
(이미지 크기를 384x384로 하는 이유에 대해서는 아래에서 설명하겠다.)
def normalize(dataset):
image, label = tf.cast(dataset['image'], tf.float32), dataset['label']
image=(tf.image.resize(image, [384,384]))/255.0
return image, label이 함수를 prefetchdataset에 적용하기 위해서는 아래와 같이 map함수를 사용한다.
batch함수는 32만큼 묶음처리한다는 의미.
train_dataset = raw_train.map(normalize).batch(32)
test_dataset = raw_test.map(normalize).batch(32)이렇게 변형한 데이터셋의 shape를 확인하려고 하니 아래와 같은 에러가 뜬다.

batchDataset은 shape를 확인할 수 없다는 뜻..ㅋ
그래서 아래와 같은 코드를 통해 shape를 확인해야 한다.
#shape 확인
for image_batch, label_batch in train_dataset.take(1):
pass
image_batch.shape데이터셋의 하나를 이용하여 대표로 shape를 확인하는 방식.

첫 번째 숫자는 batch사이즈
두 번째, 세 번째 숫자는 이미지 가로, 세로 크기
네 번째 숫자는 컬러 이미지임을 뜻함.
지금까지가 텐서플로우 데이터 셋 전처리 작업이었고 이제 모델링 하는 방법에 대해 소개하겠다.
전이학습을 이용하여 위 데이터셋을 분류하는 모델을 만들어 보겠다
텐서플로 허브에 나와있는 모델을 전이에 이용한다.
https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_s/feature_vector/2
TensorFlow Hub
tfhub.dev
import tensorflow_hub as hub
inception_url = 'https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet21k_ft1k_s/feature_vector/2'
feature_model = tf.keras.Sequential([
hub.KerasLayer(inception_url, input_shape=(384,384,3), output_shape=(1280,), trainable=False)
])
feature_model.build([None, 384,384, 3])
feature_model.summary()위 모델 설명 페이지에 가보면 해당 모델은 입력이 384x384인 이미지를 받기 때문에,
데이터 전처리 과정에서 이미지를 384x384로 리사이징을 해주었다.

모델의 summary는 위와 같다.
이 모델에 완전연결신경망 레이어를 추가하는 단계를 거친다.
파라미터 수가 큰 만큼 드롭아웃의 비율을 0.5로 설정한다.
데이터셋의 라벨 수가 9이기 때문에 마지막 레이어의 unit은 9로 설정한다.
model = tf.keras.Sequential([
feature_model,
tf.keras.layers.Dense(256, activation='relu', input_shape=(1280,)),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(9, activation='softmax')
])만든 모델을 컴파일 해주고 최종 모델의 summary를 확인한다.
model.compile(tf.optimizers.RMSprop(0.0001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
history = model.fit(train_dataset, validation_data=test_dataset, epochs=50, batch_size=32)아까 전처리 했던 데이터들을 그대로 넣어서 학습을 시켜주면 문제 없이 잘 학습이 된다.

이전 포스팅에서 데이터셋을 numpy로 변형 후 학습시키느라 굉장히 번거로웠지만
오늘 포스팅에서는 매우 간단한 방법으로 텐서플로 데이터셋을 전처리하고 학습시키는 법을 알아보았다.
'대학원 공부 > 텐서플로' 카테고리의 다른 글
| [에러] AttributeError: 'Tensor' object has no attribute 'numpy' (0) | 2023.01.02 |
|---|---|
| [에러] Please ensure this object is passed to the `custom_objects` argument. (0) | 2022.12.09 |
| [Tensorflow] 텐서플로 데이터셋 불러오기 (2) | 2022.11.29 |